


Legendagem automática bilingue: a ideia é simples, a solução nem tanto

![]()
Oferecer ao espectador legendas automáticas ao vivo não é novidade, mas você pode confiar o suficiente em tecnologias de IA para legendar programas em dois idiomas? Carmen Pérez Cernuda, vice-diretora da área de inovação e estratégia tecnológica da RTVE, lança luz sobre este tema.
Graças a a extensa estrutura territorial da RTVE, que tem um centro em cada uma das comunidades autónomas, é possível aproximar os cidadãos das notícias que são produzidas no seu ambiente imediato. Para isso, além de espaços de rádio, a TVE produz duas reportagens diárias em cada um dos seus centros territoriais, que são transmitidos, em simultâneo, via TDT através de desconexões territoriais, uma durante a manhã e outra ao início da tarde.
E é precisamente isso simultaneidade o que complica a legendagem destas notícias pelo Métodos tradicionais com um orçamento razoável. Por esta razão, historicamente foram legendando apenas as notícias territoriais das Ilhas Canárias, Catalunha e Madrid uma vez que, sendo Centros de Produção, existe um Sistema de legendagem manual ou semiautomático utilizado para todos os outros programas.
Introdução à automação
A ideia de Automatize a legendagem Surgiu cedo, mas o desafio não foi trivial uma vez que, e como um pequeno aparte, para aqueles menos familiarizados com o tema da legendagem, entre os quais confesso que até há pouco tempo também lá estive, direi que há um Regulamentos rigorosos (UNE 153010/2012, bem como o código de boas práticas do Centro Espanhol de Legendagem e Audiodescrição, CESyA) que define de forma ampla e muito específica uma multiplicidade de parâmetros, tais como: Densidade de legendagem (como uma percentagem de tudo o que é discutido no programa), Atraso máximo entre a palavra e o texto, número máximo de letras por linha e linhas, tempo de permanência mínimo e máximo na tela de texto, Localização da legenda no ecrã, etc. que devem ser cumpridos para assegurar a compreensão e o acompanhamento do que é falado.
Após algumas provas de conceito e períodos de adaptação, um Serviço de legendagem automática (…) . Hoje, este é um serviço consolidado com níveis de qualidade por mesmo acima do esperado.
Assim, foi só em 2018, quando o estado da arte das tecnologias da fala e da inteligência artificial aplicada ao processamento de linguagem natural atingiu um Grau de maturidade Isso encorajar-nos-ia a aventurar-nos no Legendagem automática de programas noticiosos viver com Uma certa garantia de sucesso. Estas características dos programas acrescentam algumas dificuldades à automação; ser notícia implica que há momentos em que o Os oradores não são profissionais e a tomada de som não é realizada nas melhores condições ambientais, posição do microfone, etc. Além disso, estando ao vivo, implica que você tenha um curto espaço de tempo, apenas alguns segundos, para o Obtenção e exibição da legenda.
Após algumas provas de conceito e períodos de adaptação, um Serviço de legendagem automática cujos níveis de qualidade foram Pelo menos igual aos restantes sistemas de legendagem utilizados até então. Hoje, este é um serviço consolidado com níveis de qualidade por mesmo acima do esperado.
E porque não em centros bilingues?
No entanto, nessa altura a falta de modelos linguísticos noutras línguas faladas em Espanha e a dificuldade acrescida das alterações linguísticas impossibilitou o alargamento do serviço às notícias bilingues.
Depois de algumas tentativas falhadas, finalmente, em 2020 obtivemos, através de um concurso público, uma empresa capaz de gerar um serviço como o que exigimos em espanhol e as línguas faladas em espanhol. Navarra, País Basco, Ilhas Baleares, Comunidade Valenciana e Galiza, de modo que a legenda gerada foi escrita na mesma língua em que estava sendo falada.
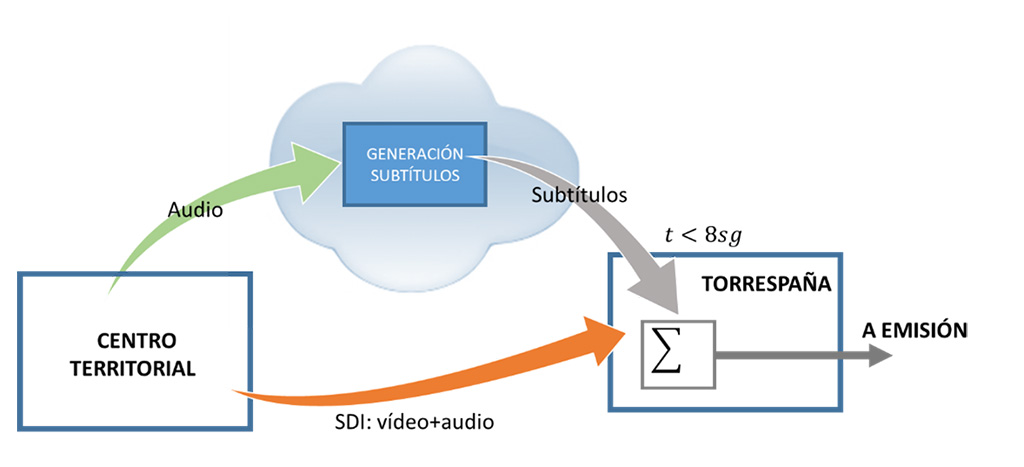
Como no caso da notícia em espanhol, foi proposto desde o início que o serviço seria em nuvem, para que a RTVE entregue o sinal áudio do Territorial News, em banda base através do Interface de áudio digital AES3, no Centro onde é produzido. A empresa responsável pelo serviço realiza o processamento necessário para a geração de legendas automaticamente, em tempo real e com Reconhecimento da Língua Falada, apoiando-se apenas no som ao vivo do programa, uma vez que não conta com a ajuda de sistemas de informação prévios, tais como guiões de notícias, resumos, etc.
As legendas geradas para todos os Centros são entregues ao CPP de Torrespaña (Madrid), em DVB sobre IP, para incorporação na rede TDT.
Os Centros Territoriais que utilizam este novo sistema são os da Comunidade Valenciana, das Ilhas Baleares, da Galiza, do País Basco e de Navarra, que foram incorporados por fases, a uma taxa de um por mês, a partir de Fevereiro de 2021, uma vez validados os resultados em cada caso através do controlo de qualidade correspondente.
Um sistema de alarme automatizado permite-lhe Conhecimento de eventuais erros ao longo de toda a cadeia de serviço, que, em caso de avaria, também desliga o equipamento de legendagem. O serviço é prestado por Aicox como empresa integradora aplicando a tecnologia de Etiqmedia para o processamento e geração de legendas.
Como é gerada a legendagem bilingue?
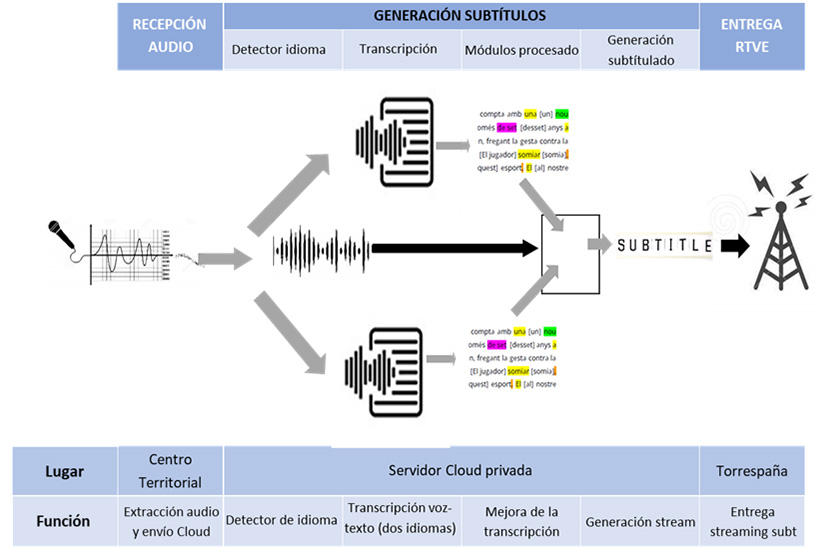
Para cada Centro, a solução tem Dois sistemas de processamento funcionando em paralelo, uma para cada uma das duas línguas faladas em cada programa noticioso. Neste processo, transcreve-se o seguinte Conversão de fala em texto, você passa pelo dicionário, pelo módulo de capitalização e pontuação, pelo módulo de apresentação numérica e outros que aplicam regras para melhorar alguns erros, sempre tendo em mente que em todas essas fases você tem que ser Muito cuidado com atrasos que introduzem por se tratar de legendagem ao vivo. Aspirar a uma qualidade muito boa em qualquer um deles, significa adicionar segundos que penalizam muito a experiência do usuário pode até não cumprir os regulamentos.
Além disso, e como peça fundamental do sistema, existe o módulo de deteção de linguagem falada, que, tendo em conta as características acústicas e aplicando tecnologias baseadas em redes neuronais, em apenas cinco segundos tem de decidir se a língua em que fala é A ou B, assim, selecionando em que idioma as legendas são apresentadas a qualquer momento. Da mesma forma, o fato de ser "ao vivo" condiciona os parâmetros que podem ser Ajuste no detetor para melhorar seu funcionamento.
Nem todos os noticiários bilingues são iguais...
Embora a estrutura do noticiário territorial, em termos de O conteúdo é o mesmo em todos os centros (títulos, peças editadas, algumas ao vivo, tempo, cultura e desporto), no que diz respeito à língua Eles não seguem nenhum padrão comum, o que torna os resultados da legendagem automática inconsistentes.
Assim, em alguns centros, tais como Navarra e o País Basco, todas as notícias são realizadas em espanhol, exceto Um resumo das notícias no final do jogo que é dado em basco; além disso, no caso de Navarra, só é feito no noticiário da tarde.
Uma das nossas preocupações é conseguir Distinguir erros atribuíveis ao detetor de linguagem e os que estão ao mesmo tempo Modelo de linguagem
Em outros, praticamente todas as notícias são faladas no língua da Comunidade e só é convertido para espanhol quando há algum Intervenção de figuras públicas, sondagens de rua, etc. No meio-termo estaria a notícia de que, embora o fio condutor esteja num Língua única, Cada peça ou afirmação pode estar em uma ou outra, dependendo do autor da mesma.
Também acontece frequentemente que, ao falar numa língua, Algumas palavras são ditas na outra língua. Isto ocorre, embora não só, com Nomes de entidades (organizações, localidades...), situação que naturalmente acrescenta Alguma dificuldade para o reconhecedor da língua.
No caso de Galiza onde está o com um forte sotaque em galego, O detetor de linguagem, que funciona com fonemas, tem muitas dificuldades em distinguir quando ocorre uma mudança de idioma, especialmente na transição do galego para o espanhol. No entanto, em Navarra, em que se encontra a seringa O basco é aquele falado com um acentuado sotaque castelhano, no se ha conseguido que el sistema reconozca el cambio de idioma. Para paliar la situación en este Centro concreto, dada su casuística, estamos trabajando para que el cambio de idioma se haga recurriendo a un módulo de detección de ráfagas.
 Seguimiento y parámetros de calidad
Seguimiento y parámetros de calidad

Otra pieza clave del proyecto es el exhaustivo control de calidad que se lleva a cabo y cuyos resultados sirven no solo para conocer la calidad de la solución sino para, detectando los puntos débiles, contribuir a la mejora del funcionamiento de la herramienta y por tanto de los niveles de calidad obtenidos.
Para ello, una empresa especializada, Aptent, que cuenta con expertos en todas las lenguas tratadas, Analisa dois fragmentos de cinco minutos do News Weekly de cada Centro Territorial em que tanto o dia da semana como a hora da notícia são variados: no início, no meio ou no fim, fazendo para cada fragmento um conjunto de medições objetivas, recolhidas num relatório semanal que inclui também os erros mais marcantes que foram detetados.
Uma das nossas preocupações é conseguir Distinguir erros atribuíveis ao detetor de linguagem e os que estão ao mesmo tempo Modelo de linguagem. Para saber exatamente a qualidade do modelo linguístico, algumas premissas foram estabelecidas, como não levar em conta o Primeiros cinco segundos Toda vez que há uma mudança de idioma (lembre-se que é a janela que foi estabelecida para o detetor decidir em qual idioma ele é falado e, portanto, contém erros). Por outro lado, os Palavras afetadas quando há uma alteração de idioma não detetada ou adicionada pelo sistema.
Conhecer a qualidade da transcrição, diferenciando para cada uma das línguas, o Taxa de erro por palavra (WER), que tem em conta palavras adicionadas, suprimidas ou transcritas erradamente em relação ao número total de palavras reais. Um Precisão de cálculo, que além dos erros acima, leva em conta os de pontuação e capitalização.
No que diz respeito ao funcionamento do detetor de línguas, ele leva em conta as mudanças que não foram detetadas e aquelas que o sistema considerou uma mudança de idioma sem realmente existir, em comparação com as mudanças reais, analisando separadamente os erros na mudança do espanhol para a outra língua e os contrários.
Além disso, nas mesmas amostras, um Acompanhe o tempo necessário para que as legendas apareçam na tela já que o áudio foi ouvido.
 Alguns resultados
Alguns resultados

Em geral, observamos que os melhores resultados são obtidos quando Analise o início da notícia, os piores correspondem ao Fragmentos do seu fim, mientras que, cuando se analiza la parte central, los resultados varían mucho en función del contenido de estos fragmentos. Este es un comportamiento esperado, ya que el inicio del informativo se corresponde con la lectura por un profesional de un texto previamente redactado, por tanto, lenguaje estructurado y en un plató, es decir, con buena captación del audio, mientras que los fragmentos de la parte central suelen ser intervenciones con lenguaje natural, a veces desde la calle, por hablantes no profesionales y donde las condiciones acústicas son peores. La parte final del informativo normalmente corresponde al tiempo, deportes y cultura donde aparecen con mucha frecuencia nombres propios locales, con poca frecuencia de aparición, en los que estos sistemas son menos eficaces. Puede haber una diferencia de 2 a 5 puntos en la tasa de error WER entre el inicio y el final de los informativos.
Para el castellano se utiliza el mismo modelo de lenguaje, entrenado con miles de horas, para todas las comunidades sin que los resultados sean homogéneos. Los mejores resultados se obtienen en Navarra y P. Vasco, donde en más del 90% de las medidas realizadas, se obtiene un WER menor que 8% incluso en las partes mas complejas del informativo. La Comunidad Valenciana obtiene un WER por debajo del 10%, mientras que Galicia y Baleares tienen un comportamiento muy irregular y a veces, siempre hablando de los fragmentos analizados, hay tan pocas palabras en castellano, que no es posible hacer un cálculo de WER fiable en este idioma.
En cuanto al resto de idiomas, se obtienen estos resultados: euskera, el WER se mantiene por debajo del 15% en el 90% de las muestras. Comunidad Valenciana, WER menor que el 25% si es la parte final y el 15% si es en el inicio; Galicia, WER menor que el 20% en la parte final y el 15% en el resto; y Baleares, menor que el 20% en la parte final e inicial y muy irregular en el medio del informativo.
En lo referente a la precisión, la mayor cantidad de errores está en la capitalización y puntuación, fluctuando entre el 40 y el 50% así como en las palabras transcritas de forma incorrecta, entre el 25 y el 35%. A mucha distancia están las palabras perdidas, alrededor del 10%, siendo prácticamente insignificantes las palabras añadidas.
El detector de idioma tiene un comportamiento desigual en las distintas lenguas con resultados diferentes si el paso es de castellano a la lengua local, que si es en el sentido contrario, afectando a su funcionamiento también cuando, en un cambio de idioma, el fragmento que se habla en el idioma al que se ha cambiado es de pocos segundos.
En cuanto al tiempo de presentación en pantalla, cuyo máximo está en fijado en 8 segundos y, aunque en los inicios del proyecto estaba bastante próximo a esta cifra, ha ido mejorando y en la actualidad estamos entre los 5 y 6 segundos de media.
Qué podemos esperar
O sistemas de redes neuronales aplicados a este tipo de casos de uso han supuesto una espectacular mejora en los resultados obtenidos respecto a otras tecnologías anteriores, sin embargo, tienen la contrapartida de que necesitan grandes cantidades de datos para su entrenamiento. Uno de los problemas más importantes en los idiomas tratados, a excepción del castellano, es que se dispone de muy pocos datos para poder entrenar. Por lo tanto, ya se esperaban resultados desiguales, según el idioma, ya que unos modelos de lenguaje podrían estar más o menos entrenados que otros, en función de trabajos o encargos ya prestados anteriormente en dichos idiomas, publicaciones de corpus abiertos, etc.
Por otro lado, y al tratarse de programas en directo, algunas fórmulas de mejora como la introducción de reglas posteriores a la transcripción solo se pueden aplicar cuando son muy sencillas porque, en caso contrario, penaliza el tiempo de entrega de los subtítulos.
Confiamos en que las capacidades computacionales continuarán incrementándose permitiendo introducir fórmulas más complejas para la mejora en la precisión e o tiempo de presentación en pantalla.
Al margen del avance de los modelos de lenguaje en los distintos idiomas, que se producirá, sin duda, con el incremento en el uso de sistemas de este tipo para diversas aplicaciones que dará lugar a que se disponga cada vez de más y más horas para entrenamiento, esperamos que tanto en la capitalización y puntuación con las nuevas tecnologías basadas en Transformers, como otras aplicadas a la detección de idioma, consigan un incremento apreciable en la calidad de los subtítulos obtenidos.
Por otro lado, confiamos en que las capacidades computacionales continuarán incrementándose permitiendo introducir fórmulas más complejas para la mejora en la precisión e o tiempo de presentación en pantalla.
Todos los motivos expuestos pero, sobre todo, el acercamiento de algunas asociaciones de personas sordas para felicitarnos porque por primera vez pueden seguir un informativo en su lengua materna, hacen que todo el esfuerzo invertido en este proyecto haya merecido la pena y nos aporta toda la motivación necesaria para continuar apostando por el mismo.
Carmen Pérez Cernuda
Subdirectora del área de innovación y estrategia tecnológica en RTVE

Gostou deste artigo?
Subscreva o nosso NEWSLETTER e você não vai perder nada.
Outros artigos relacionados
 8 Fevereiro 2023 RTVE e UCLM promovem conferência focada na inovação audiovisual
8 Fevereiro 2023 RTVE e UCLM promovem conferência focada na inovação audiovisual 1 Outubro 2020 Aicox lleva a cabo el subtitulado automático de los Centros de RTVE con informativos bilingües
1 Outubro 2020 Aicox lleva a cabo el subtitulado automático de los Centros de RTVE con informativos bilingües 21 Maio 2019 RTVE adjudica a Aicox Soluciones el Lote 2 del sistema de monitorado y supervisión para su Red de Centros Emisores de RNE
21 Maio 2019 RTVE adjudica a Aicox Soluciones el Lote 2 del sistema de monitorado y supervisión para su Red de Centros Emisores de RNE 16 Abril 2019 Aicox suministra a RTVE más de trescientos receptores de satélite para América
16 Abril 2019 Aicox suministra a RTVE más de trescientos receptores de satélite para América 1 Abril 2019 RTVE renueva el sistema de ingesta masiva de la mano de Aicox Soluciones y Harmonic
1 Abril 2019 RTVE renueva el sistema de ingesta masiva de la mano de Aicox Soluciones y Harmonic 7 Março 2019 Los Telediarios de TVE implantan la inteligencia artificial con Etiqmedia y Aicox
7 Março 2019 Los Telediarios de TVE implantan la inteligencia artificial con Etiqmedia y Aicox 22 Novembro 2018 Aicox, Etiqmedia, Harmonic y VSN analizan el impacto de la nube y la inteligencia artificial en el sector
22 Novembro 2018 Aicox, Etiqmedia, Harmonic y VSN analizan el impacto de la nube y la inteligencia artificial en el sector 20 Novembro 2018 Aicox organiza un seminario sobre gestión avanzada de contenidos, tráfico y producción en cloud
20 Novembro 2018 Aicox organiza un seminario sobre gestión avanzada de contenidos, tráfico y producción en cloud 19 Setembro 2018 RTVE renueva de la mano de Aicox Soluciones sus codificadores de emisión online con equipos Haivision
19 Setembro 2018 RTVE renueva de la mano de Aicox Soluciones sus codificadores de emisión online con equipos Haivision 31 Maio 2018 RTVE congrega a la industria en un workshop sobre producción sobre entornos IP
31 Maio 2018 RTVE congrega a la industria en un workshop sobre producción sobre entornos IP 24 Maio 2018 Aicox Soluciones exhibió en BIT Audiovisual sus últimas propuestas de sus divisiones de satélite y broadcast
24 Maio 2018 Aicox Soluciones exhibió en BIT Audiovisual sus últimas propuestas de sus divisiones de satélite y broadcast 23 Abril 2018 Aicox Soluciones exhibirá en BIT Audiovisual sus soluciones para 4K, IP, cloud e inteligencia artificial
23 Abril 2018 Aicox Soluciones exhibirá en BIT Audiovisual sus soluciones para 4K, IP, cloud e inteligencia artificial