


Proyecto Vision: un ambicioso proyecto de telepresencia inmersiva
Tras cuatro años de intenso trabajo, acaba de finalizar con notable éxito Vision, un proyecto CENIT del Ministerio español de Industria, Turismo y Comercio, gestionado por el CDTI, cuyo objetivo ha sido desarrollar una nueva generación de sistemas de comunicación que permitiera transmitir la sensación de presencia real, de manera que que las personas separadas por grandes distancias percibieran la sensación de estar físicamente reunidas en un mismo lugar tanto en entornos domésticos, pymes o grandes empresas.

En 2007 nacía VISION, un proyecto CENIT del Ministerio de Industria, Turismo y Comercio, gestionado por el CDTI enmarcado dentro del proyecto Ingenio 2010 del Gobierno español para incrementar la inversión en I+D, tanto pública como privada.
El proyecto, que ha tenido una duración de 4 años, ha tenido como objetivo desarrollar una nueva generación de sistemas de comunicación que permitiera transmitir la sensación de presencia real, de manera que que las personas separadas por grandes distancias percibieran la sensación de estar físicamente reunidas en un mismo lugar tanto en entornos domésticos, pymes o grandes empresas.
El desarrollo de los sistemas de comunicación con sensación de presencia, contribuirá, sin duda, a la reducción del uso del transporte y de los desplazamientos reales, sustituyéndolos por comunicaciones virtuales que ofrezcan sin embargo las mismas sensaciones que un encuentro presencial. Estas nuevas capacidades en los sistemas de comunicación abren las puertas a nuevas formas de relación tanto profesional como personal. Posibilitará una mejora en las relaciones sociales y familiares ya se que favorecerán los encuentros inter-personales incluso entre personas separadas por grandes distancias.
Uno de los aspectos más destacados del proyecto es que se ha concibió desde un punto de vista multi-empresa, multi-universidad y plurisectorial liderado por Telefónica I+D en el que han participado una docena de empresas como ADTEL, AD Telecom, Alcatel-Lucent, Anafocus, Brainstorm, DS2, Eptron, Ericson, PREVI, SAPEC, Solex Visión Artificial y Telnet. Por citar solo algunos de los centros universitarios y tecnológicos destacaremos la presencia en el proyecto de la Fundación I2CAT, el Instituto de Ciencias Fotónicas, VivomTech y las universidades de Valladolid, Cantabria, Carlos III, Jaume I, Autónoma de Madrid y las Politécnicas Cataluña, Valencia y Madrid.
Para poder evaluar los resultados de los estudios teóricos el proyecto llevó a cabo en las instalaciones de Telefónica I+D un sistema demostrador donde se pudiera evaluar de forma práctica los resultados teóricos obtenidos en áreas como la captura de realidad, el procesado AV, las tecnologías avanzadas de comunicación y de presentación de la realidad.

Desarrollo del proyecto
El presupuesto global del proyecto Vision ha sido de 33 millones de euros, subvencionado en el 49.23% por el CDTI, participando unas 90 personas al año (más el personal aportado por las universidades asociadas) en cada uno de los cuatro años en los que se ha desarrollado.
El primer año del proyecto se dedicó a su lanzamiento y estudio de requisitos e interfaces. EL segundo año se focalizó en la investigación (estado del arte, funcionalidades, algoritmos, equipamiento…). Un año más tarde, el esfuerzo se centró en la integración de cada pieza, empezando a trabajar con los algoritmos, implantarlo, mejorarlos, pasando así de algo téorico a algo práctico capaz de correr en tiempo real. El último año se puso en marcha el demostrador final en el que poner en práctica todos los avances.
Ahora, una vez concluidos los primeros cuatro años del proyecto es de esperar que todo el trabajo desarrollado, con el que el CDTI ha quedado gratamente satisfecho, continúe, abriendo nuevas líneas de trabajo e investigación para el futuro plasmando todo este esfuerzo en soluciones prácticas a nivel comercial.
Para tener una idea de todo el esfuerzo que este proyecto ha supuesto, valga con decir que se han generado 195 informes (de los 139 inicialmente comprometidos), 130 activos experimentales (había comprometidos 81), 21 reuniones plenarias del consorcio y 6 solicitudes de patentes por parte de TID, ALU, Sapec y AD Telecom.
Los tres escenarios de demostración en los que se ha centrado el proyecto son: residencial, entertainment y PYME, y grandes empresas.
En entornos residenciales, el objetivo ha sido contar con una videoconferencia 3D de alta calidad con mínimos recursos pero diferencial de las existentes comercialmente. Para ello, sólo se han empleado un set frontal 3D con dos cámaras ofreciendo una visualización 3D con y sin gafas. Para estos entornos se ha desarrollado una interacción gestual (interfaz hombre-máquina), un complejo sistema de sonido 3D (síntesis de audio para recibir audio espacial coherente según el posicionamiento del interlocutor) y un práctico sistema para compartición simultánea de fotos, vídeos… con el otro extremo de la aplicación.
Otro de los escenarios sobre el que el proyecto Vision ha trabajado es el de la PYME a fin de ofrecer nuevas posibilidades más allá de la videoconferencia en escenarios de entertainment, formación… En este caso, se trabaja con varias cámaras con mayor complejidad de captura y comunicaciones a fin de contar con una videoconferencia inmersiva de alta calidad.
Partiendo de dos cámaras frontales y 18 cámaras reales se recrean cientos de puntos de cámara virtuales que aportan una conferencia inmersiva 3D multipunto (con tecnologías VC 3D y Free View Pint Video) y con varios escenarios virtuales 3D. La interfaz gráfica permite cambiar elementos gráficos en GUI,puntos de vista, grabaciones de sesiones….
En un escenario corporativo, el proyecto se ha enfocado en ofrecer una videoconferencia inmersiva de alta calidad orientada al sector empresarial con posibilidad de gestionar reuniones y llevar a cabo videoconferencias 3D multipunto con sonido 3D y escenarios virtuales seleccionables.
En un entorno colaborativo de trabajo (edición y visualización simultánea de contenidos 3D en tiempo real), quienes participan en la videoconferencia cuentan siempre con la posición relativa de los usuarios y un análisis de escena presencial que aumenta aún más la sensación inmersiva. Incluso se pueden recrear avatares fotorrealista de las personas que intervienen montando un avatar 3D partiendo de fotos.
[youtube]http://www.youtube.com/watch?v=sGWymOgjp9o[/youtube]
")
Captura de la realidad
Uno de los aspectos más interesantes de este proyecto ha sido el desarrollo de métodos y tecnologías para la adquisición digital de escenarios, lugares, ambientes, a fin de conseguir captar aspectos de la realidad que hasta ahora no han sido tenidos en cuenta en las comunicaciones.
Basándose en una arquitectura multicámara este desarrollo permite obtener y digitalizar modelos tridimensionales de la realidad. Un mar de cámaras (con 18 unidades) permite capturar la escena en una sala en la que se invirtió mucho esfuerzo para su diseño y dimensionamiento cuidando todos los detalles como una cubierta antireflectante, un sistema de iluminación, una estructura metálica y un sistema de anclajes para la sujección de las cámaras, junto con las cámaras y cables necesarios.
La utilización de un número tan elevado de cámaras hace imprescindible diseñar un sistema de sincronización del disparo de las cámaras que garantice que todas ellas capturan coordinadamente toda la escena.
En el proyecto se ha especificado, diseñado y construido un sistema distribuido de disparo, capaz de generar frecuencias de disparo diferentes para cada grupo de cámaras.
Para asegurar la perfecta calibración de las cámaras, el proyecto ha desarrollo sistemas, tanto manuales como automáticos, que permitan de la forma más sencilla y rápida posible obtener los parámetros intrínsecos y extrínsecos de las cámaras. Para ello, se han valorado algoritmos de gran precisión espacial (precisión subpíxel) y temporal.
En el proyecto también se han investigado y diseñado tecnologías para la creación de sistemas de adquisición de vídeo que permitan satisfacer las exigencias computacionales y de latencias en servicios de tiempo real como los especificados en VISION. El resultado de esta actividad es un sistema experimental de captura en tiempo real compuesto principalmente de un front-end basado en cámaras con sensores CMOS de altas prestaciones conectadas a través de interfaces estándar de alta velocidad a la plataforma de computación e integradas en un sistema experimental de captura con algoritmos de procesado multimedia en tiempo real.
[youtube]http://www.youtube.com/watch?v=ae9S_pZBZSY[/youtube]
")
Análisis y procesado de vídeo
El proyecto ha servido también para desarrollar avanzadas tecnologías de análisis y procesado de vídeo que permitan enriquecer las imágenes capturadas posibilitando la percepción de la realidad por el usuario final y combinándola con elementos virtuales generados sintéticamente.
Obteniendo la base algorítmica del sistema de captura audiovisual a partir de los captura multicámara permitirá, en tiempo real, la construcción de un modelo tridimensional de la realidad puede transmitirse a un interlocutor remoto para crear en este último un sentimiento de presencia física. Para ello, los investigadores han desarrollado modelos para identificar el fondo de escena y extraer el primer plano de las imágenes. La extracción de primer plano es una herramienta imprescindible para obtener posteriormente el Visual Hull mediante la técnica de Shape from Silhouette.
Se han implementado diferentes métodos de extracción (segmentación) de las regiones de interés del primer plano (RdI) observado desde la perspectiva de cada cámara utilizando modelos estadísticos del fondo de escena. Estos algoritmos proporcionan una máscara binaria (también llamada silueta) y un mapa que indica la probabilidad de que cada píxel de la imagen pertenezca a la clase “silueta / objeto” o a la clase “fondo de escena”.
Por otro lado, el sistema permite la obtención de mapas de profundidad (la inversa de la disparidad) utilizando tanto una captura binocular como multi-cámara. En captura binocular se han prototipado diferentes implementaciones de algoritmos (correlación de fase, “rubber-matching”, “graph cuts”, y otros), y se ha analizado las implicaciones computacionales y arquitecturales de dichas implementaciones en tiempo real.
En captura multi-cámara se ha explorando la generalización de los algoritmos anteriores trabajando sobre tríos de cámaras como primitivas de adquisición. Para el análisis volumétrico se han implementado algoritmos de reconstrucción volumétrica del tipo “Shape from Silhouette” (SfS), que permiten obtener el Visual Hull a partir de la intersección de todos los conos de reproyección originados a partir de de las siluetas de cada cámara.
Partiendo de los algoritmos de Visual Hull, se ha llevado a cabo el reconocimiento semántico e interfaces gestuales a fin de permitir añadir inteligencia al sistema a diversos niveles: apoyo a la reconstrucción, integración de elementos sintéticos, interacción con el usuario, generación de servicios de valor añadido,… Así, se logra la localización, reconocimiento y seguimiento de objetos y personas, la identificación de la actividad humana (con especial atención a los interfaces gestuales) y el reconocimiento de comportamientos e interacción basado en ontologías de dominio
Para conseguir un efecto inmersivo, el audio juega también un papel fundamental. Por ello, se ha desarrollado un sistema de sonido capaz de reproducir en una sala las mismas sensaciones acústicas que una persona tendría si estuviese en otra sala, complementando así al procesado de la componente de vídeo para conseguir el sistema de comunicación con sensación de presencia.

")
Comunicación
Obviamente, un proyecto de este calibre no tendría sentido sin la garantía de poder unir dos puntos remotos con los estándares y tecnologías actuales en lo que respecta a la gestión conjunta de múltiples flujos de vídeo, el elevado ancho de banda, la ultra baja latencia y la oferta de servicios que ayuden a mejorar la interacción de los usuarios.
La codificación, donde la tecnología de la empresa Sapec ha sido determinante , es el primer paso en la transmisión de la información. En este ámbito se ha planteado la investigación de nuevos codificadores de vídeo multivista y nuevos codificadores de vídeo de alta calidad así como de sistemas de codificación eficiente de flujos múltiples de vídeo. Uno de los principales objetivos es minimizar el retardo de codificación con el fin de evitar el impacto en la transmisión extremo a extremo y mejorar así la interactividad para servicios conversacionales. Se ha realizado un estudio detallado de la codificación de vídeo MPEG-2 y H.264, habiéndose optado por utilizar H.264/AVC, con su extensión MVC (MultiView Video Coding).
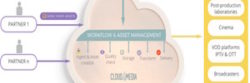
La red de comunicaciones que se desarrolla en el proyecto es una red de alta capacidad y ultra baja latencia capaz de satisfacer los estrictos requisitos de QoS demandados. Para ello ha sido necesario garantizar el perfil de QoS que requieren los diferentes flujos multimedia, no solo en la red de acceso, sino también en las redes de distribución y del núcleo de red.
La arquitectura de la red de comunicaciones está basada en el modelo de NGN (Next Generation Networks) propuesto por TISPAN. Este modelo estructura la arquitectura de la red de comunicaciones en tres niveles: el nivel de acceso, el nivel de control y el nivel de aplicación. Las capas de transporte y control proporcionan las funciones de switching y routing avanzadas, y la capa de control del acceso implementa, entre otras, las funciones de control de acceso (subsistema NASS) y gestión de recursos y calidad de servicio (subsistema RACS).
![]()
Presentación de la realidad
El proyecto VISION ha investigado técnicas innovadoras que permitan reconstrucciones realistas de escenas capturadas por sistemas de comunicación de video de nueva generación, así como diseñar y desarrollar un display 3D capaz de representar una imagen tridimensional desde cualquier ángulo de vista a una distancia variable del espectador.
En el ámbito de las tecnologías de reconstrucción realistas se ha avanzado en la búsqueda de avances en gráficos en tiempo real para la síntesis de escenas, investigando en técnicas de realidad mixta para la reconstrucción remota de escenarios que incluyan elementos virtuales compartidos por los distintos interlocutores.
La adquisición tridimensional, una vez codificada y transmitida, genera la fuente de datos que alimenta los algoritmos de representación. Debido a las propias técnicas de captura empleadas, estas topologías no pueden consistir siempre en geometrías poligonales y esto hace imposible emplear directamente algoritmos tradicionales de representación, por tanto, se establece una importante línea de investigación en este campo. A priori se esperan tres topologías distintas en la información capturada y por tanto se estudian técnicas de síntesis correspondientes a cada caso: obtención de matrices de vóxeles, algoritmos que permitan obtener geometrías poligonales a partir de nubes de puntos y por último representación de escenas basadas en múltiples flujos de video con información 3D adicional (puntos característicos y profundidad de cada píxel).
Una vez realizada la renderización para la representación de los modelos tridimensionales, por ejemplo con el método del “Marching Cubes”, se realiza la proyección de texturas recibidas del sistema de captura. En el proyecto se ha trabajado en diferentes algoritmos para la proyección de textura, habiéndose implementado inicialmente un algoritmo de proyección de textura única sobre el volumen a través de “shaders”.
Para lograr una sensación de realidad inmersiva, se integran elementos reales y virtuales dentro de una misma escena. Gracias al procedimiento de captura es posible conocer las posiciones de los elementos capturados respecto de un sistema de referencia global, este hecho hace posible integrar elementos sintéticos localizados de tal manera que coexistan en la escena con los elementos reales. Para obtener una mejor integración entre imágenes sintéticas y reales se han estudian algoritmos de incrustación, de ajuste de color y de render que permitan conseguir el máximo realismo alcanzable utilizando Chromakey.
Además, en este proyecto se han investigando los equipos de visualización encargados de mostrar el resultado gráfico final, lo que puede llevar a métodos especiales de renderización que puedan satisfacer los requerimientos de la imagen a visualizar.
En cuanto de displays, en el proyecto se ha trabajado con monitores convencionales 2D, 3D y 3D autoesteroscópico evitando el uso de gafas.
Sapec, en el proyecto VISION
Sapec, como la primera y única compañía española que ha diseñado sistemas de compresión de vídeo MPEG2 y H.264, ha participado activamente en el desarrollo del proyecto VISION aportando su experiencia y recursos en la investigación de sistemas de compresión.
La fuerte apuesta de Sapec por la I+D, que supera el 20% de su cifra de negocio y el 30% de su plantilla, es una de las señas de identidad de esta empresa que cuenta con una completa gama de soluciones tanto para redes de contribución como distribución de señales.
Sapec ha contado para este proyecto con la colaboración del Grupo de Tratamiento de Imágenes (GTI) de la E.T.S. de Ingenieros de la Politécnica de Madrid. Este grupo cuenta con una gran experiencia en seguimiento y contribución a grupos de estandarización de codificación de vídeo.
El reto que se planteaba era analizar e investigar nuevos algoritmos de codificación de video que permitieran transportar por redes IP de nueva generación, señales de video que provenían de múltiples cámaras para proporcionar sensación de realidad de la comunicación.
En el otro extremo dichas señales tenían que ser descomprimidas para ser presentar al usuario de forma que esa sensación de realidad fuera percibida realmente por el usuario. Finalmente deberían desarrollarse los equipos que mediante HW y SW fueran capaces de ser integrados en el demostrador y nos permitieran realizar una evaluación de los resultados de las investigaciones.
Ya que el uno de los objetivos del proyecto VISION era acercar la telepresencia no solo a entornos empresariales sino también entre usuarios, ha sido necesario investigar soluciones, algoritmos y alternativas para reducir al máximo el ancho de banda (buscando la compresión más adecuada para mantener la calidad subjetiva del vídeo) a muy baja latencia (manteniendo la sensación de realidad) y con perfecta sincronización e interoperabilidad.
Durante la marcha del proyecto, Sapec ha propuesto soluciones para la codificación, transporte, decodificación y sincronización de vídeo para visualización Free ViewPoint Video (Modelos 3D + texturas), estereoscópica (L+R) y autoestereoscópica (Vista+ Profundidad) de forma combinada.
Quizás uno de los avances más notables es el desarrollo del algoritmo de codificación H264 MVC (codificación multivista). Fruto del trabajo de investigación en el marco del proyecto Sapec ha desarrollado un método de sincronización de flujos de datos transportados por una red de Telecomunicaciones para el transporte de video sobre redes IP (en proceso de patente). Esta tecnología se ha implementado en la nueva línea de soluciones para contribución IP FastIpSync.
En el demostrador del flujo de trabajo del proyecto Vision Sapec ha integrado soluciones de hardware y software para codificación y decodificación, capaces de codificar, decodificar, transportar y sincronizar un modelo 3D de la escena (compuesto 18 vistas de video y un modelo de vóxeles), y 2 vistas estereoscópicas HD y la profundidad asociada a las mismas codificadas en H264 MVC y transportadas según el estándar MPEG-C todo funcionando a tiempo real.
Estos sistemas integrados en el demostrador, partiendo de la señal de las 18 cámaras, han codificado y decodificado vídeo tanto en la visualización Free View Point Video (18 texturas con codificación H264 y vóxeles con codificación runlength) como en la visualización frontal 3D (2 views+depth), llevando a cabo la sincronización de todos los flujos de vídeo y permitiendo la transmisión de todos ellos a través de protocolos IP. Por otro lado, estos sistemas han servido para negociar la selección de vistas para la renderización de las texturas de vídeo.

Avez-vous aimé cet article ?
Abonnez-vous à notre BULLETIN et vous ne manquerez de rien.
Articles connexes
 Canal+ amène le MotoGP dans une nouvelle expérience immersive pour Apple Vision Pro avec Blackmagic Design
Canal+ amène le MotoGP dans une nouvelle expérience immersive pour Apple Vision Pro avec Blackmagic Design
 UHD sur la CRTVG : la première étape d'un plan ambitieux
UHD sur la CRTVG : la première étape d'un plan ambitieux
 ‘Balenciaga’, un ambicioso proyecto de Disney+ España, refuerza su equipo creativo
‘Balenciaga’, un ambicioso proyecto de Disney+ España, refuerza su equipo creativo
 Mediawan étend sa présence en Espagne avec un pôle de production ambitieux
Mediawan étend sa présence en Espagne avec un pôle de production ambitieux
 France Télévisions elige a Arkena para su ambicioso proyecto de SVOD
France Télévisions elige a Arkena para su ambicioso proyecto de SVOD
![El Día Más Corto [ED+C]](https://www.panoramaaudiovisual.com/wp-content/uploads/2017/10/El-Dia-Mas-Corto-250x134.png) El ICAA iniciará un ambicioso proyecto internacional para impulsar el cortometraje
El ICAA iniciará un ambicioso proyecto internacional para impulsar el cortometraje
 Coppola apuesta por el mezclador DYVI de EVS para su más ambicioso proyecto
Coppola apuesta por el mezclador DYVI de EVS para su más ambicioso proyecto
 Carlos Slim se asocia con Larry King para lanzar un ambicioso proyecto de IPTV
Carlos Slim se asocia con Larry King para lanzar un ambicioso proyecto de IPTV
 Vietnam Television escoge a Jampro para un ambicioso proyecto de antenización
Vietnam Television escoge a Jampro para un ambicioso proyecto de antenización
 Cisco lleva la telepresencia a cualquier tipo de organización
Cisco lleva la telepresencia a cualquier tipo de organización
 Polycom lanza nuevas opciones para telepresencia
Polycom lanza nuevas opciones para telepresencia
 PI@: un ambicioso impulso a la industria audiovisual en San Sebastián
PI@: un ambicioso impulso a la industria audiovisual en San Sebastián
 Las últimas propuestas de telepresencia en ISE 2010
Las últimas propuestas de telepresencia en ISE 2010
 Cisco lleva la telepresencia al hogar
Cisco lleva la telepresencia al hogar