


自动双语字幕:想法很简单,解决方案并不多

![]()
为观众提供自动实时字幕并不是什么新鲜事,但人工智能技术是否值得信赖,能够为节目提供两种语言的字幕? Carmen Pérez Cernuda,创新与技术战略领域副主任 RTVE,阐明了这个主题。
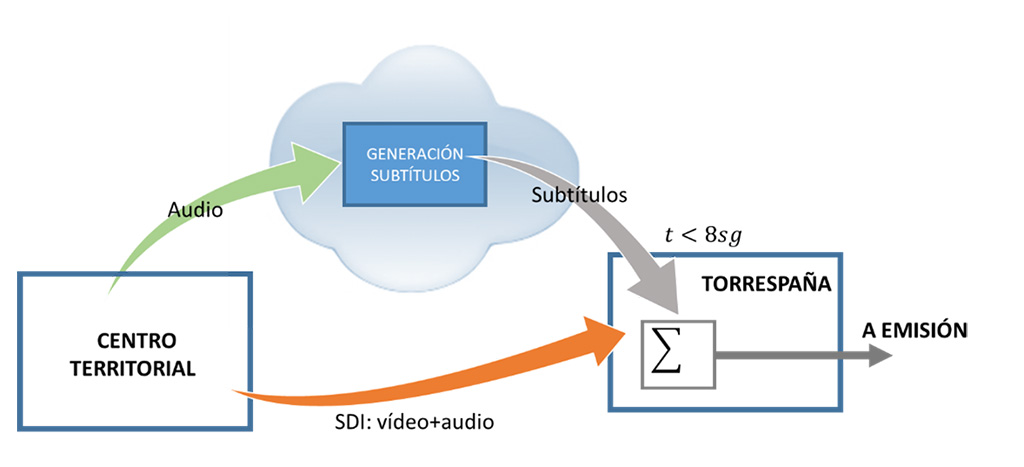
由于 广阔的领土结构 RTVE 在每个自治区都设有一个中心,可以让公民更近距离地了解发生在他们周围的新闻。为此,除了广播空间外,TVE 还制作 每日两则新闻报道 在其每个地区中心,通过地区中断通过 DTT 同时广播,一个在上午,另一个在下午开始。
而正是这个 同时性 这使得这些新闻的字幕变得复杂 传统方法 有合理的预算。正因如此,历史上他们 仅加那利群岛、加泰罗尼亚和马德里的领土新闻字幕 因为作为生产中心,有一个 用于其余节目的手动或半自动字幕系统。
自动化的第一步
的想法 自动字幕 它很快就出现了,但挑战并不是微不足道的,因为对于那些不太熟悉字幕主题的人来说,我承认直到最近我也发现自己,我会说有一个小问题 严格规定 (UNE 153010/2012,以及西班牙字幕和音频描述中心 CESyA 的良好实践准则),它广泛且非常具体地定义了许多参数,例如: 字幕密度 (占节目中讨论的所有内容的百分比), 单词和文本之间的最大延迟, 每行最大字母数和 线, 最短和最长停留时间 在文本屏幕上, 屏幕上的字幕位置等必须满足的 确保理解和跟进 所说的内容。
经过一些概念测试和调整期后, 自动字幕服务 (……)。如今,这是一项综合服务,其质量水平由 甚至高于预期。
因此,直到 2018 年,应用于自然语言处理的语音技术和人工智能的最先进水平才达到了 成熟度 这鼓励我们冒险进入 新闻节目自动字幕 与 成功的一定保证。这些程序特性给自动化增加了一些困难;提供信息意味着有时 演讲者不是专业人士 和声音摄入量 不是在最佳环境条件下进行、麦克风位置等。此外,由于是直播,因此意味着存在 短时间内,只需几秒钟,对于 获取字幕并在屏幕上呈现。
经过一些概念测试和调整期后, 自动字幕服务 其质量水平是 至少相等 到那时使用的其余字幕系统。如今,这是一项综合服务,其质量水平由 甚至高于预期。
为什么不在双语中心呢?
然而,当时 西班牙使用的其他语言缺乏语言模型 而且语言转换的难度增加,导致无法将服务扩展到双语新闻节目。
经过几次失败的尝试后,最终在 2020 年,通过公开招标,我们获得了一家能够提供我们所需的西班牙语和其他语言服务的公司。 纳瓦拉、P. Vasco、巴利阿里群岛、C. 瓦伦西亚和加利西亚,以便生成的字幕将以与所说的语言相同的语言书写。
与西班牙语新闻的情况一样,从一开始就提议该服务将在 云,以便 RTVE 通过基带传送领土新闻的音频信号 AES3 数字音频接口,就在它的生产中心。负责服务的公司 进行必要的处理 用于自动、实时地生成字幕 口语识别,仅依靠节目的现场声音,因为它没有以前的信息系统的帮助,例如新闻脚本,节目单等。
为所有中心生成的字幕均在 托雷斯帕尼亚 CPP (马德里),格式 DVB 清醒 IP,用于合并到 DTT 图中。
使用这一新系统的领土中心是巴伦西亚自治区、巴利阿里群岛、加利西亚、巴斯克地区和纳瓦拉的领土中心,这些中心以每月一个的速度分阶段合并,因为 2021 年 2 月,一旦通过相应的质量控制在每种情况下验证了结果。
自动警报系统可让您 了解任何错误 贯穿整个服务链,此外,如果发生故障,也会断开字幕设备的连接。提供服务 艾科克斯 作为一家应用技术的综合性公司 埃蒂克媒体 用于处理和生成字幕。
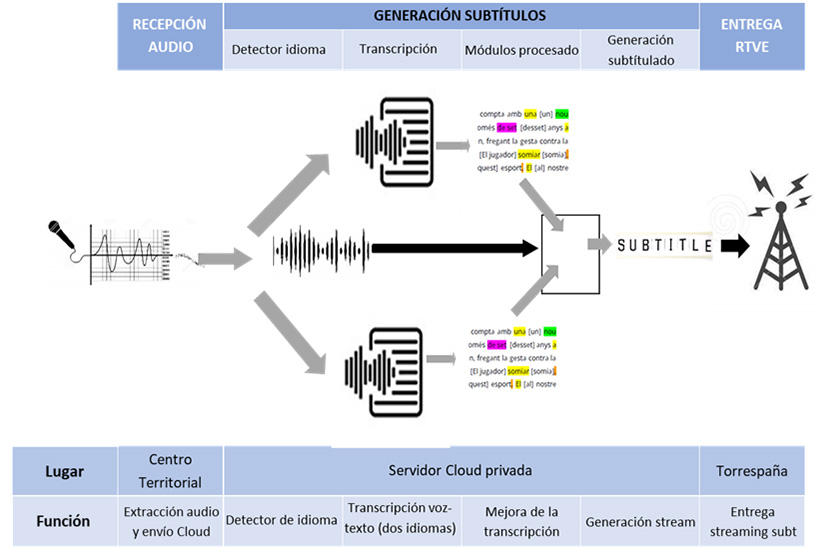
双语字幕是如何生成的?
对于每个中心,解决方案有 两个并行运行的处理系统,每条新闻中使用的两种语言各一个。在此处理中,它被转录 语音转文字,你会浏览字典、大小写和标点符号模块、数字表示模块以及其他应用规则来改进一些错误的模块,始终记住,在所有这些阶段中,你必须 非常小心延误 他们在现场字幕方面介绍了这一点。追求其中任何一个方面的优良品质意味着 增加几秒,极大地影响用户体验 可能不遵守规定。
此外,作为系统的基础部分,还有口语检测模块,该模块考虑到声学特性,应用基于神经网络的技术,仅 五秒钟你必须决定所说的语言是 A 还是 B, 从而选择始终显示字幕的语言。同样,“实时”这一事实决定了可以 调整探测器以提高其性能。
并非所有双语新闻节目都是一样的......
尽管从地域新闻的结构来看, 所有中心的内容都相同 (头条新闻、剪辑片段、一些现场表演、时间、文化和体育),关于语言 他们不遵循任何共同的模式,导致自动字幕的结果不一致。
因此,在一些中心,例如 纳瓦拉和巴斯克地区,所有信息均以西班牙语完成,除了 结尾处用巴斯克语给出的新闻摘要;更重要的是,就纳瓦拉而言,这只是在下午的新闻中进行的。
我们关心的问题之一是电力 区分由语言检测器引起的错误 以及那些 语言模型
在其他情况下,几乎所有新闻都在 社区语言 他们只有在有一些情况时才切换到西班牙语 公众人物的介入、街头调查等。处于中间立场的是新闻节目,尽管共同点是 唯一的语言, 每一篇文章或陈述都可以属于其中之一,具体取决于其作者。
也经常发生这样的情况,当用一种语言说话时, 有些词是用另一种语言说的。这种情况发生的情况不仅限于 实体名称 (组织、地方……),这种情况自然会增加 语言识别器有一定的难度。
如果是 加利西亚, 在哪里讲的 带有浓重加利西亚口音的西班牙语, 与音素一起工作的语言检测器有 区分语言何时发生变化有很多困难,尤其是从加利西亚语到西班牙语的过渡。然而,在 纳瓦拉,哪里是 巴斯克语带有明显的卡斯提尔口音,系统无法识别语言更改。为了缓解这个特定中心的情况,鉴于其诡辩,我们正在努力使 语言更改是通过突发检测模块来完成的。
 监测和质量参数
监测和质量参数

该项目的另一个关键部分是 详尽的质量控制 执行的结果不仅可以了解解决方案的质量,还可以通过检测薄弱点, 有助于改善该工具的功能 以及因此获得的质量水平。
为此,一家专业公司, 他们适合,拥有涵盖所有语言的专家, 分析每周新闻的两个五分钟片段 每个区域中心的星期几和新闻时间都不同:在开始、中间或结束时,对每个片段进行一组客观测量,收集在每周报告中,其中还包括已检测到的最显着的错误。
我们关心的问题之一是电力 区分由语言检测器引起的错误 以及那些 语言模型。为了准确地了解语言模型的质量,已经建立了一些前提,例如不考虑 前五秒 每次发生语言变化时(我们记得这是为检测器建立的窗口来决定使用哪种语言,因此包含错误)。另一方面,那些 受影响的词 当系统未检测到或添加语言更改时。
要了解转录的质量,区分每种语言, 每个单词的错误率 (WER),它考虑了添加、删除或错误转录的单词与实际单词总数的关系。还有一个 精密计算,除了前面的错误之外,还考虑了标点符号和大小写错误。
关于语言检测器的操作,将未检测到的变化和系统认为实际存在的语言变化与实际变化进行比较,分别分析从西班牙语到其他语言的变化以及相反的变化中的错误。
此外,在相同的样品上, 跟踪字幕出现在屏幕上所需的时间 自从听到声音后。
 一些结果
一些结果

一般来说,我们观察到,当 分析新闻的开头,最差的对应于 其末尾的片段,而当分析中心部分时,根据这些片段的内容,结果会有很大差异。这是预期的行为,因为新闻的开头对应于 由专业人士阅读先前撰写的文本因此,结构化语言在一个场景中,即具有良好的音频捕获,而中心部分的片段往往是自然语言的干预,有时来自街道,由非专业演讲者进行,并且声学条件较差。新闻的最后部分通常对应于它们经常出现的天气、体育和文化。 当地专有名称,很少发生,其中这些系统的效率较低。可能存在差异 新闻开头和结尾之间的 WER 错误率为 2 到 5 分。
对于西班牙语来说, 相同的语言模型为所有社区进行了数千个小时的培训,但结果却不尽相同。最好的结果是在 纳瓦拉和 P. 瓦斯科,在超过 90% 的测量中,即使是新闻中最复杂的部分,WER 也低于 8%。巴伦西亚社区的 WER 低于 10%,而加利西亚和巴利阿里群岛的行为非常不规则,有时,总是谈到分析的片段,西班牙语中的单词太少,以至于无法用这种语言进行可靠的 WER 计算。
至于其余语言,获得以下结果:巴斯克语,90% 的样本中 WER 保持在 15% 以下。 巴伦西亚社区,最后部分WER低于25%,开头部分低于15%;加利西亚,最后部分WER低于20%,其余部分15%;巴利阿里群岛,最后和最初部分不到20%,而且新闻中间非常不规则。
关于 精确,错误数量最多的是 大写和标点符号,在 40% 到 50% 之间波动,而在错误转录的单词中,则在 25% 到 35% 之间波动。丢失的单词远远落后,约为 10%,而添加的单词几乎微不足道。
语言检测器有一个 不平等的行为 如果从西班牙语过渡到当地语言,则在不同的语言中会产生不同的结果,而不是在相反的方向上,当在语言变化中,用已更改的语言说出的片段只有几秒钟时,也会影响其功能。
关于屏幕呈现时间,最大值设置为 8秒 而且,尽管在项目开始时它非常接近这个数字,但它一直在改进,目前我们属于 平均5秒和6秒。
我们可以期待什么
洛斯 神经网络系统 应用于此类用例意味着 惊人的进步 然而,在相对于其他先前技术获得的结果中,他们有他们需要的对应物 大量数据供您训练。除西班牙语外,所处理的语言中最重要的问题之一是 需要训练的数据很少。因此,根据语言的不同,已经预料到会出现不平等的结果,因为根据先前以所述语言、开放语料库出版物等提供的工作或作业,某些语言模型可能比其他语言模型接受更多或更少的训练。
另一方面,事实上 直播节目,一些改进公式如 引入转录后规则 它们只能在非常简单的情况下应用,否则会影响字幕的交付时间。
我们相信 计算能力 将继续增加允许引入 更复杂的公式 为了改善 精确 和 演示时间 在屏幕上。
除了不同语言的语言模型的进步(毫无疑问,随着此类系统在各种应用程序中的使用增加,这将导致可用于培训的时间越来越多),我们希望基于新技术的资本化和评分 变形金刚与其他应用于语言检测的方法一样,在 获得的字幕质量。
另一方面,我们相信 计算能力 将继续增加允许引入 更复杂的公式 为了改善 精确 和 演示时间 在屏幕上。
所有的理由都给出了,但最重要的是 一些聋人协会的做法 祝贺我们,因为他们第一次可以用自己的母语观看新闻节目,他们使整个 在这个项目上投入的努力是值得的 并给我们所有 必要的动机 继续投注它。
卡门·佩雷斯·塞尔努达
中科院创新科技战略领域副主任 RTVE

你喜欢这篇文章吗?
订阅我们的 通讯 你不会错过任何东西。
相关文章
 Vicomtech 和 RTVE 展示他们在使用人工智能自动字幕方面的进展
Vicomtech 和 RTVE 展示他们在使用人工智能自动字幕方面的进展
 RTVE 和 Vicomtech 完善自动字幕
RTVE 和 Vicomtech 完善自动字幕
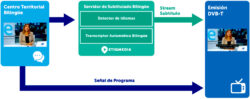 Aicox 对 RTVE 中心的双语新闻节目进行自动字幕
Aicox 对 RTVE 中心的双语新闻节目进行自动字幕
 El Terrat 开始为 Playz 拍摄双语小说“戏剧”
El Terrat 开始为 Playz 拍摄双语小说“戏剧”
 根据 Daniel Écija 的原创想法开始拍摄系列片“La Valla”
根据 Daniel Écija 的原创想法开始拍摄系列片“La Valla”
 下一站或如何将视听想法变为现实
下一站或如何将视听想法变为现实
 DSpatial:全新完整且简单的沉浸式混音解决方案
DSpatial:全新完整且简单的沉浸式混音解决方案
 Cintel 扫描仪和 Ursa 相机荣获 2015 年 IDEA 奖
Cintel 扫描仪和 Ursa 相机荣获 2015 年 IDEA 奖
 Avid 对创意社区和大型广播公司比以往任何时候都更加开放
Avid 对创意社区和大型广播公司比以往任何时候都更加开放
 Volicon 和 Nexidia 推出完整的隐藏式字幕自动化解决方案
Volicon 和 Nexidia 推出完整的隐藏式字幕自动化解决方案
 OnTimeLS:最终一个有效、经济且简单的广播中音频和视频同步解决方案
OnTimeLS:最终一个有效、经济且简单的广播中音频和视频同步解决方案
 新型电视节目实时自动字幕系统
新型电视节目实时自动字幕系统
 Ikan 销售一种提示解决方案,为现场和工作室提供最大的灵活性
Ikan 销售一种提示解决方案,为现场和工作室提供最大的灵活性
 Softel ScheduleSmart:自动实时字幕
Softel ScheduleSmart:自动实时字幕