


“Evergreen content” = (File + AI) x SEO. A simple but effective algorithm
Artificial Intelligence opens an opportunity for collaboration between technology and media companies to bring their content to life.

If there is one issue that defines and gives value to a medium, it is its contents. It is the supply, quantity and quality of the information o entertainment offered what makes the difference, positive or negative, compared to other alternatives. All these contents are a very valuable heritage that is stored in the files, departments that, although discreet compared to others in the world of media, are the memory that allows us to know who we are, where we come from or the origin of many stories that are current news today.
In them we find “archive” stories that enrich and complement news or entertainment. But there are many opportunities that they can offer beyond being a material for regular use as support for current content. Tools for Artificial intelligence (IA) in documentary collections, either for automatic metadata, for searches or for managing large amounts of data, among others.
evergreen content
During the pandemic caused by coronavirus The contents called “evergreen“, which in Spanish could be translated as contents “perennials” o “timeless". Its name comes from the evergreen plant, which retains its green leaves throughout the year, and are those that, being neither current nor archival, are never outdated and deal with issues that are relevant to the audiences.
This is information that has been in high demand since the beginning of the COVID-19 pandemic, such as, for example, being in better physical condition, how to telework, how to create more suitable spaces in our homes, how to cook healthier, etc. There are two very relevant issues in them: the content, which is relevant even if the years pass, and the topics, those that always have interest and a significant search volume regardless of the moment in which we find ourselves.
There are many tools IA In the market, there is a lot of demand for content and many of these contents are in our files but there is no specific solution to facilitate this work, or generate recommendations or specific content for specific audiences.
For this, tools could be used that analyze the SEO of our content and the traffic of our media to see what interests the public, systems that analyze what people search for in the web, reading, listening and/or watching (topics/subjects) as well as in social networks. So, wouldn't we have a very powerful tool if AI mixed them to recommend, retrieve or generate specific, new content adapted to demand?
The challenge
Answering questions like this has been the objective of the international team of media professionals in which he has participated RTVE inside the JournalismAI Collab, a project of the Polis Studies Center of the London School of Echonomics that is supported by the Google News Initiative. Collab is an experiment collaboration in which different news organizations from around the world, by type of media, size, audience, etc. have come together to explore innovative solutions to improve journalistic activity using AI.
The objective on which we have worked has been possible use of AI to generate this type of content taking advantage of existing files and to know whether or not there were tools on the market that provided a response by creating useful, well-positioned content, with impact and that responded to the demand - high, as we have seen - that exists among the audience.
The final report suggests that news organizations should work with technology companies to examine these needs so they can help develop new possibilities y tools. We've spoken to some of the top companies in the sector and here are some of their ideas.
The opinion of the specialists
To Richard Benjamins, Chief AI & Data Strategist in Telefónica, Spanish multinational company located among the main telecommunications companies in the world, a solution could be found by following two paths.
The first would be to define what “evergreen” content is (in terms of words, images, video or sound) and, automatically, with machine learning, categorize as such those that are considered that way and, the second, train a algorithm con Deep Learning on a document base that serves as a reference and then pass the complete repository.
Both may be possible. The question would be how good it is, and if this is enough for it to systematically provide value. In the end we talk about the knowledge management of a company, a field in which successes are few, although technically achieving it is possible.
Telefónica, which is dedicated to providing services, has a unit dedicated to Big Data and AI. Currently they do not work with projects linked to “evergreen data”, but in the future they could be interested seeing that it is an attractive field, which could have a welcome and future in the market.
Benjamins considers it important, to define a valid product, to complete tests with users and define its explainability, what its daily use would be like. “The technology is there, it wouldn't be difficult to do.”, he assures.
Narrative, AI company specialized in automatic generation of content, considers that this type of content is not only useful, but is the future, both for companies and for the media.
“The digital transformation that has been experienced in recent years and that has accelerated with the pandemic confirms the absolute prominence of digital media, so mere online presence is no longer enough: it is necessary to be relevant,” he says. David Llorente, CEO and founder of Narrativa.
However, when generating this type of content they find two main difficulties. La primera es que muchas compañías invierten actualmente una gran cantidad de tiempo, dinero y recursos en la generación de contenido manual. Esto supone desarrollar los textos manualmente e implica una menor agilidad en el proceso. En segundo lugar, generar contenido no es suficiente, necesita cumplir una serie de requisitos según las necesidades del medio/empresa para poder aparecer en los motores de búsqueda.
En Narrativa están desarrollando ya este tipo de tecnología, combinar palabras clave específicas destinadas a un mejor posicionamiento SEO. Las etiquetas que emplean van dirigidas a búsquedas muy concretas por parte de los usuarios en los motores de búsqueda.
De esta manera, los resultados son mucho más ajustados a lo que los posibles clientes quieren encontrar. Recientemente, han generado descripciones de automóviles para un cliente que han logrado situarse directamente dentro de los 10 primeros resultados que arroja Google.
Por lo tanto no sólo sería factible, sino que además sería rentable para las empresas, que ahorrarían tiempo y costes. Las herramientas que otorga la inteligencia artificial, afirman, permitirían contar con un contenido “evergreen” de mayor variedad y permitiría a los periodistas centrarse en tareas de un mayor valor añadido.
La aplicación de técnicas de inteligencia artificial ofrece ventajas indudables en muchas áreas, como el procesamiento de lenguaje natural, pero el problema de identificar contenido evergreen es potencialmente complejo y difícil de formular, considera José Manuel Gómez-Pérez, Director Language Technology Research of Expert.AI.
A priori, podemos pensar que se puede resolver entrenando desde cero un modelo que, dado un documento, lo clasifique como evergreen o no. Si asumimos que el contenido en sí es suficiente para resolver el problema y que no sería necesario por ejemplo datos sobre el impacto generado por ese contenido a lo largo de una franja de tiempo significativa, un enfoque como este parece viable.
Sin embargo, se enfrenta a una variedad de retos, como por ejemplo la generación de un corpus de documentos lo suficientemente grande y su correspondiente etiquetado para entrenar el modelo. Es técnicamente factible, cree, pero necesita resources para generar ese conjunto de datos y etiquetarlo, tarea que puede suponer una investment significativa dependiendo del volumen que sea necesario extraer y anotar.
Parece mucho más interesante, afirma, aplicar técnicas basadas en modelos pre-entrenados que sólo necesiten ajustarse para esta tarea concreta o aplicar enfoques basados en reglas formuladas por un ingeniero de conocimiento que reflejen su comprensión de lo que puede ser un contenido evergreen.
En Expert.AI se han enfrentado a problemas similares en ámbitos como el análisis de narrativas yihadistas o la detección y análisis de disinformation en medios online. A su manera, tanto las narrativas como los temas básicos en los que se centra la desinformación, son contenido evergreen destinado a captar la atención de su público objetivo de manera atemporal. La solución óptima pasa por establecer una alliance entre la inteligencia artificial y los usuarios a los que asiste, un partnership que revierta en sistemas de IA que se alimenten del feedback de los usuarios, ofreciendo cada vez mejores predicciones.
La empresa de tecnología danesa Spor.ai aconseja devolver la capacidad de decisión al periodista y, después, de dejar que la IA genere una lista de sugerencias basadas en una o varias combinaciones a las que se podría afinar introduciendo un conjunto de filtros.
Una posibilidad podría ser mostrar los desplegables regulares, aunque Spor.ai cree más conveniente mostrar el cálculo como un gráfico de conocimiento. Se podría entonces editar y filtrar las relaciones entre las entidades que definen el resultado en la pantalla del gráfico. Esto mantendría la visión general de las relaciones elegidas que son más difíciles de ver con los filtros regulares.
Conclusiones del grupo
Aunque no terminamos de desarrollar una herramienta universal imaginaria, a la que llamamos “ArcAI”, sí que logramos reunir muchas experiencias y conocimientos valiosos que demuestran que es posible construir soluciones para aprovechar los archivos empleando herramientas o soluciones basadas en IA y, que, aunque sea en parte, algunas que ya existen podrían ser útiles. También descubrimos una serie de retos, limitaciones y algunas preguntas básicas para responder al qué se quiere lograr.
Hay un gran potencial en el archivo, pero ¿cuáles son las necesidades específicas de cada redacción? No hay razón para desarrollar una herramienta de investigación avanzada si lo que se necesita es introducir una etiqueta de metadatado para un tipo específico de contenido o definir simples notificaciones cíclicas. Diferentes redacciones tienen diferentes necesidades, así como diferentes definiciones y objetivos de lo que este tipo de contenidos evergreen significan realmente para cada una de ellas.
Dado que hay muy pocas herramientas disponibles se debería decidir qué solución se necesita. Cuanto más avanzados sean los métodos técnicos, más trabajo de desarrollo requerirá.
Usando el Procesamiento de Lenguaje Natural (PNL), el Reconocimiento de Entidades Nombradas (NER) y el Aprendizaje Automático/ Machine Learning (ML) en combinación con el etiquetado manual y/o los filtros de gráficos de conocimiento, se puede obtener resultados bastante precisos en los archivos. Pero, ¿sería suficiente con poner un campo de búsqueda en el sistema de gestión de contenidos, el CMS? ¿Cuáles son los criterios que deberían calificar a una buena coincidencia? ¿Cuánto trabajo de filtrado pondrá en manos del periodista?
Cuando se trabaja con el archivo es fundamental tener una buena coherence y estructura en la base de datos y los metadatos. Cuanto mejor sea la estructura, más fácil será aprovechar la base de datos con el uso de herramientas de Inteligencia Artificial.
Para implementar una herramienta como esta, ya sea basada en sistemas de etiquetado manual, métodos de exploración o cualquier otra tecnología, se necesita también contar con el apoyo de la organización y sus profesionales. Desarrollar estas herramientas para que finalmente sean un despilfarro de tiempo, recursos y dinero no tiene sentido si chocan y son anuladas por determinadas “culturas” empresariales o por la nula la motivación e implicación de sus teóricos usuarios.
En el caso de medios no angloparlantes es determinante tener en cuenta el idioma si se decide utilizar algunas de las tecnologías del mercado, como Parse.ly o Chartbeat, ya que sus algoritmos, en la mayoría de los casos, han sido entrenados en inglés o en chino y son considerablemente mejores que en otros idiomas. Sea una tecnología propia o ajena, lo más recomendable es entrenar la herramienta con el contenidos de los archivos propios para obtener el resultado más acorde a las necesidades.
Among the opportunities está la posibilidad de notificar a los periodistas cuándo el contenido anterior está reapareciendo en los motores de búsqueda; obtener mejor posicionamiento SEO, sugerir historias relacionadas y relevantes o reutilizar elementos de contenidos anteriores para crear líneas de tiempo u otros formatos, entre otras muchas.
Quizá el principal resultado del trabajo de nuestro equipo sea el solicitar a las compañías tecnológicas que se involucren y unan fuerzas con los medios de comunicación para desarrollar herramientas accesibles que den vida a los contenidos ya publicados y ayuden a poner el enorme potencial de los archivos en los contenidos periodísticos.
David Corral
Innovación RTVE
Artículo originalmente publicado en el Observatorio para la innovación de los Informativos en la Sociedad Digital (OI2)

Did you like this article?
Subscribe to our NEWSLETTER and you won't miss anything.
Related articles
 Sevilla Content City will be managed and operated by Secuoya Content Group
Sevilla Content City will be managed and operated by Secuoya Content Group
 The UPC, seeking to improve the algorithm to detect false images
The UPC, seeking to improve the algorithm to detect false images
 Moncada and Lorenzo propose a simple but complete production set for streaming
Moncada and Lorenzo propose a simple but complete production set for streaming
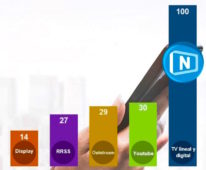 Television is the most effective medium in terms of notoriety
Television is the most effective medium in terms of notoriety
 Rushprompter: a simple prompter for less than a hundred dollars
Rushprompter: a simple prompter for less than a hundred dollars
 Newtek MediaDS effectively democratizes video encoding and streaming
Newtek MediaDS effectively democratizes video encoding and streaming
 EVS makes live production in 4K and over IP simple, fast and productive
EVS makes live production in 4K and over IP simple, fast and productive
 Volicon Observer OTT offers effective monitoring of over-the-top services
Volicon Observer OTT offers effective monitoring of over-the-top services
 OnTimeLS: finally an effective, economical and simple solution to synchronize audio and video in broadcast
OnTimeLS: finally an effective, economical and simple solution to synchronize audio and video in broadcast
 FilmGear Easy LED, simple works
FilmGear Easy LED, simple works
 FilmGear Easy LED, simple works
FilmGear Easy LED, simple works
 Quantel QTube: a true creative and efficient workflow over IP
Quantel QTube: a true creative and efficient workflow over IP
 El Marketing de Fascinación: una forma eficaz de seducir al cliente
El Marketing de Fascinación: una forma eficaz de seducir al cliente
 VSN: automation and management, simple, effective, easy and profitable!
VSN: automation and management, simple, effective, easy and profitable!